1. ```mysql # 安装 mysql,显示 Service successfully installed. 即为成功 mysqld -install # 出现 data 文件夹,初始化数据文件 mysqld --initialize-insecure --user=mysql # 启动 mysql net start mysql net stop mysql # 进入 mysql mysql -u root -p mysql -u root -proot mysql -u root -p紧紧跟着密码 # 进入记得修改密码,可以注释掉跳过密码了,然后重启 net stop mysql net start mysql
-- 查询姓刘的同学 -- like(% 是 0 到任意一个字符)(_ 是一个字符) select `studentNo`,`studentName` from `student` where studentName like'刘%'
-- 查询姓刘的同学,名字后面只有一个字的 select `studentNo`,`studentName` from `student` where studentName like'刘_'
-- 查询姓刘的同学,名字后面只有两个字的 select `studentNo`,`studentName` from `student` where studentName like'刘__'
-- 查询名字中间有嘉字的同学 %嘉% select `studentNo`,`studentName` from `student` where studentName like'%嘉%'
-- --------- in(具体的一个或多个值) ------------ -- 查询 1001 1002 1003 号学员信息 select `studentNo`,`studentName` from `student` where studentNo in (1001,1002,1003);
-- 查询在北京的学员信息 select `studentNo`,`studentName` from `student` where `adress` in ('北京')
-- ---------- null not null ------------- -- 查询地址为空的学生 select `studentNo`,`studentName` from `student` where `adress`='' select `studentNo`,`studentName` from `student` where `adress` or `adress` isnull
-- 查询有出生日期的同学,is not null 不为空 select `studentNo`,`studentName` from `student` where `borndate` isnotnull
-- 查询没有出生日期的同学,is null 为空 select `studentNo`,`studentName` from `student` where `borndate` isnull
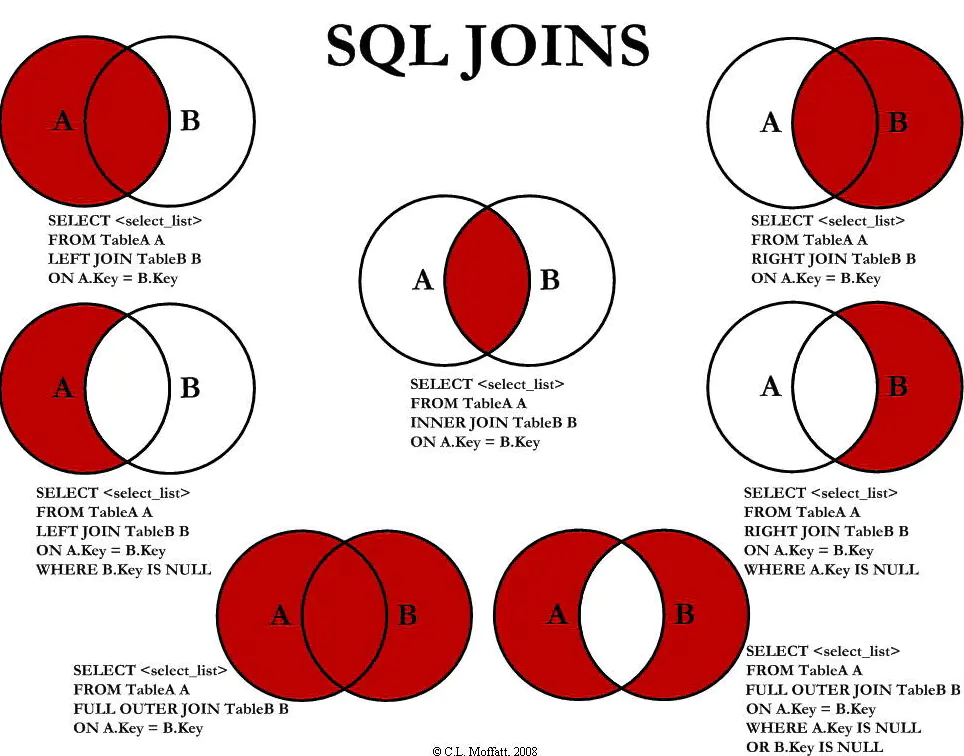
-- ==========联表查询============ -- Join(表)on (判断的条件) 连接查询 -- where 等值查询 SELECT s.studentno, studentname, subjectno, studentresult FROM student AS s INNERJOINresultAS r WHERE s.`studentno` = r.`studentno`
-- right join SELECT s.studentno, studentname, subjectno, studentresult FROM student AS s RIGHTJOINresultAS r ON r.`studentno` = s.`studentno`
-- left 左连接(查询所有同学,不考试的也会查出来) SELECT s.studentno, studentname, subjectno, studentresult FROM student s LEFTJOINresult r ON s.`studentno` = r.`studentno`
-- 查缺考的同学(左连接应用场景) SELECT s.studentno, studentname, subjectno, studentresult FROM student s LEFTJOINresult r ON s.`studentno` = r.`studentno` WHERE studentresult ISNULL
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数) SELECT s.`studentno`, `studentname`, `subjectname`, `studentresult` FROM student AS s, INNERJOINresultAS r, ON s.`studentno` = r.`studentno` INNERJOIN `subject` AS sub ON sub.subjectno = r.subjectno
-- 编写SQL语句,将栏目的父子关系呈现出来(父栏目名称,子栏目名称) -- 核心思想:把一张表看成两张一模一样的表,然后将这两张表连接查询(自连接) SELECT a.categoryname AS'父栏目', b.categoryname AS'子栏目' FROM category AS a, category AS b WHERE a.`categoryid` = b.`pid`
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数) SELECT s.studentno, studentname, subjectname, studentresult FROM student s INNERJOINresult r ON r.studentno = s.studentno INNERJOIN `subject` sub ON sub.subjectno = r.subjectno
-- 查询学员及其所属的年级(学号,学生姓名,年级名) SELECT studentno AS 学号, studentname AS 学生姓名, gradename AS 年级名称 FROM student s INNERJOIN grade g ON s.`gradeid` = g.`gradeid`
-- 查询科目及其所属年级(科目名称,年级名称) SELECT subjectname AS 科目名称, gradename AS 年级名称 FROM `subject` sub INNERJOIN grade g ON sub.gradeid = g.gradeid
-- 查询 数据库结构-1 的所有考试结果(学号,学生姓名,科目名称,成绩) SELECT s.studentno, studentname, subjectname, studentresult FROM student s INNERJOINresult r ON r.studentno = s.studentno INNERJOIN `subject` sub ON r.subjectno = sub.subjectno WHERE subjectname ='数据库结构-1'
排序和分页
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- ==========排序=========== /* 语法:order by order by 语句用于根据指定的列对结果集进行排序 order by 语句默认按照ASC升序对记录进行排序 如果希望按照 降序 对记录进行排序,可以使用 DESC 关键字 */
-- 查询 数据库结构-1 的所有考试结果(学号,学生姓名,科目名称,成绩) -- 按成绩降序排序 SELECT s.studentno, studentname, subjectname, studentresult FROM student s INNERJOINresult r ON r.studentno = s.studentno INNERJOIN `subject` sub ON r.subjectno = sub.subjectno WHERE subjectname ='数据库结构-1' ORDERBY studentresult DESC
-- ===========分页============= /* 语法:limit(起始下标, 查询长度) -- 个人觉得这样好理解 limit[pageNo:页码,pageSize:单页面显示条数] -- 原版本 好处:用户体验,网络传输,查询压力 */ -- 每页显示5条数据 SELECT s.studentno, studentname, subjectname, studentresult FROM student s INNERJOINresult r ON r.studentno = s.studentno INNERJOIN `subject` sub ON r.subjectno = sub.subjectno WHERE subjectname ='数据库结构-1' ORDERBY studentresult DESC, studentno LIMIT 0,5
-- 查询 JAVA第一学年 课程成绩前10名并且分数大于80的学生信息(学号,姓名,课程名,分数) SELECT s.studentno, studentname, subjectname, studentresult FROM student s INNERJOINresult r ON r.studentno = s.studentno INNERJOIN `subject` sub ON r.subjectno = sub.subjectno WHERE subjectname ='JAVA第一学年' ORDERBY studentresult DESC LIMIT 0,10
/*============== 子查询 ================ 什么是子查询? 在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句 嵌套查询可由多个子查询组成,求解的方式是由里及外; 子查询返回的结果一般都是集合,故而建议使用IN关键字; */ -- 查询 数据库结构-1 的所有考试结果(学号,科目编号,成绩),并且成绩降序排列 -- 方法一:使用连接查询 SELECT studentno, r.subjectno, studentresult FROMresult r INNERJOIN `subject` sub ON r.`subjectno` = sub.`subjectno` WHERE subjectname ='数据库结构-1' ORDERBY studentresult DESC
-- 方法二:使用子查询(执行顺序:由里及外) SELECT studentno, subjectno, studentresult FROMresult WHERE subjectno = ( SELECT subjectno FROM `subject` WHERE subjectname ='数据库结构-1' ) ORDERBY studentresult DESC
-- 查询课程为 高等数学-2 且分数不小于80分的学生的学号和姓名 -- 方法一:使用连接查询 SELECT s.studentno, studentname FROM student s INNERJOINresult r ON s.studentno = r.studentno INNERJOIN `subject` sub ON sub.subjectno = r.subjectno WHERE subjectname ='高等数学-2'AND studentresult >=80
-- 方法二:使用连接查询+子查询 -- 分数不小于80分的学生的学号和姓名 SELECT r.studentno, studentname FROM student s INNERJOINresult r ON s.studentno = r.studentno WHERE studentresult >=80
-- 在上面SQL基础上,添加需求:课程为 高等数学-2 SELECT r.studentno, studentname FROM student s INNERJOINresult r ON s.studentno = r.studentno WHERE studentresult >=80AND subjectno = ( SELECT subjectno FROM `subject` WHERE subjectname ='高等数学-2' )
-- 方法三:使用子查询 -- 分步写简单sql语句,然后将其嵌套起来 SELECT studentno, studentname FROM student WHERE studentno IN ( SELECT studentno FROMresult WHERE studentresult >=80AND subjectno = ( SELECT subjectno FROM `subject` WHERE subjectname ='高等数学-2' ) )
-- 练习题目:查 C语言-1 的前5名学生的成绩信息(学号,姓名,分数) SELECT s.studentno, studentname, studentresult FROM student s INNERJOINresult r ON s.studentno = r.studentno INNERJOIN `subject` sub ON r.subjectno = sub.subjectno WHERE subjectname ='C语言-1' ORDERBY studentresult DESC LIMIT 0,5
-- 练习题目:使用子查询,查询郭靖同学所在的年级名称 SELECT gradename FROM grade WHERE gradeid = ( SELECT gradeid FROM student WHERE studentname ='郭靖' )